本文PPT来自阿里云E-MapReduce团队的余根茂于10月16日在2016年杭州云栖大会上发表的《Hadoop存储于计算分离实践》。
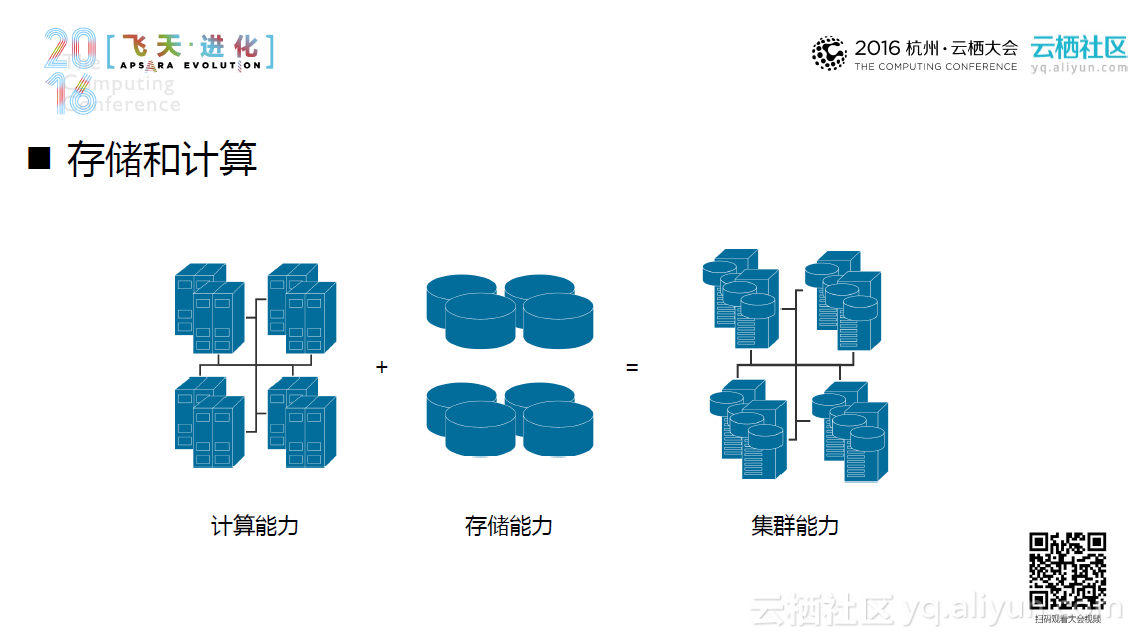
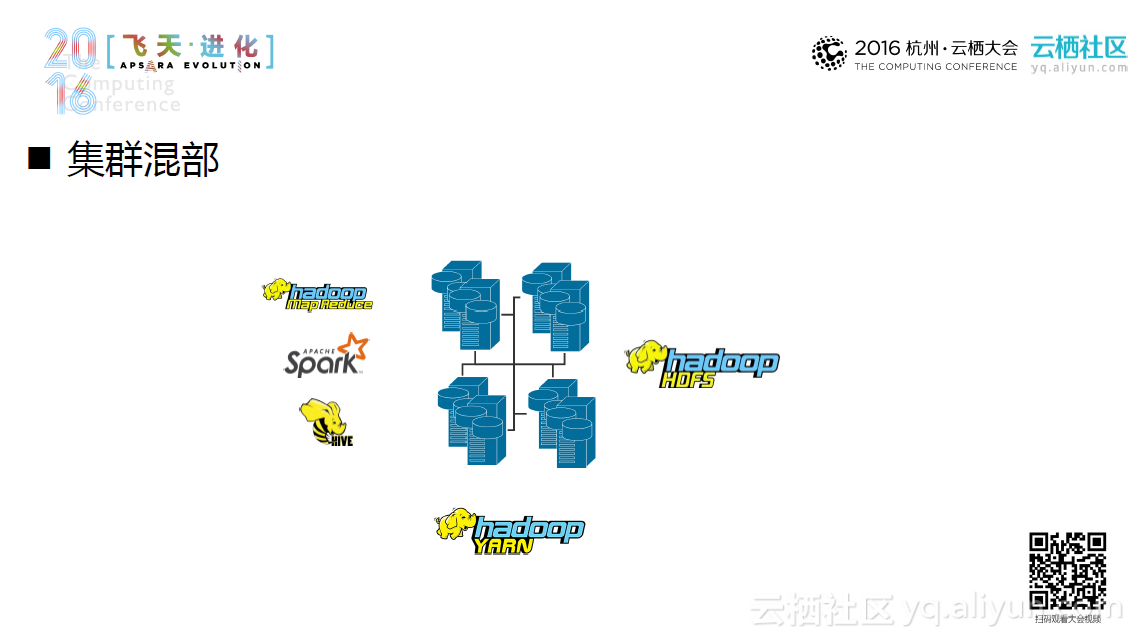
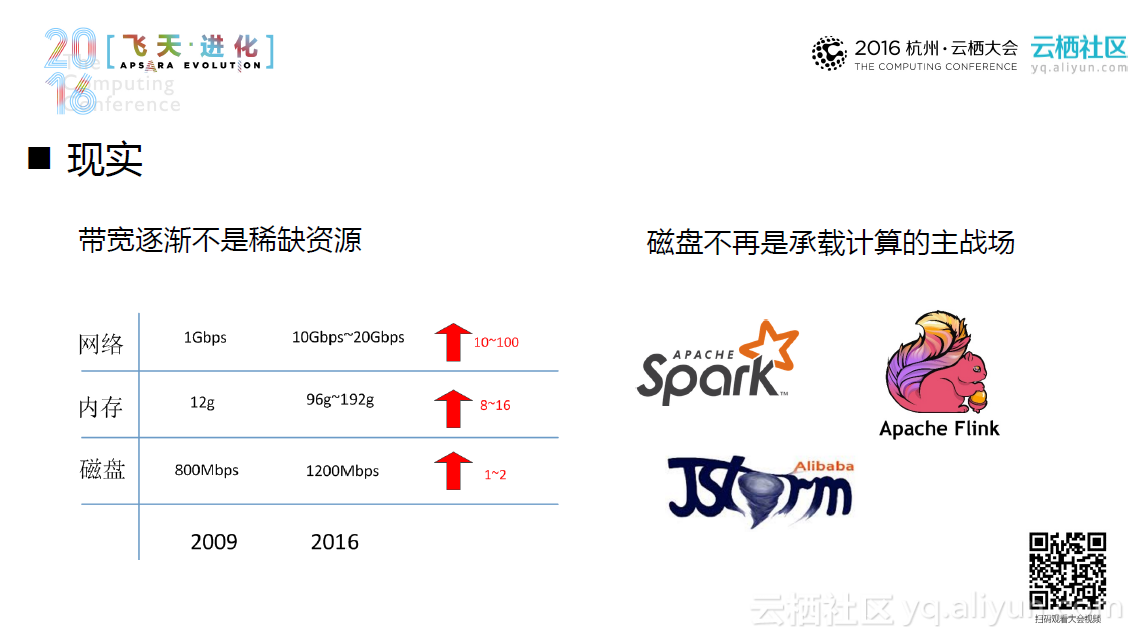
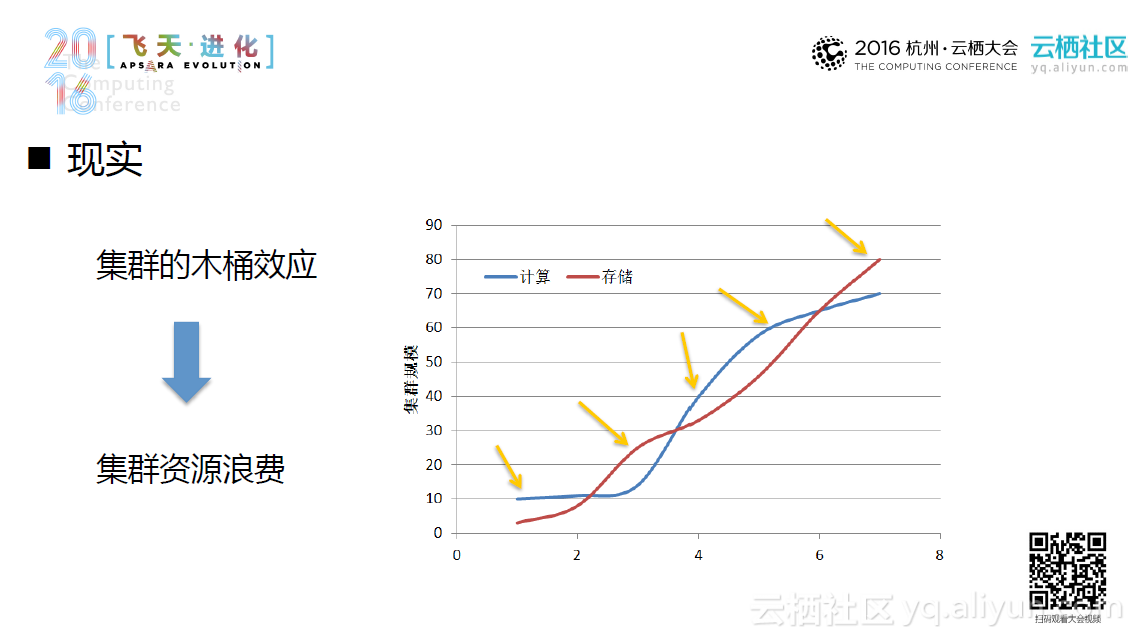
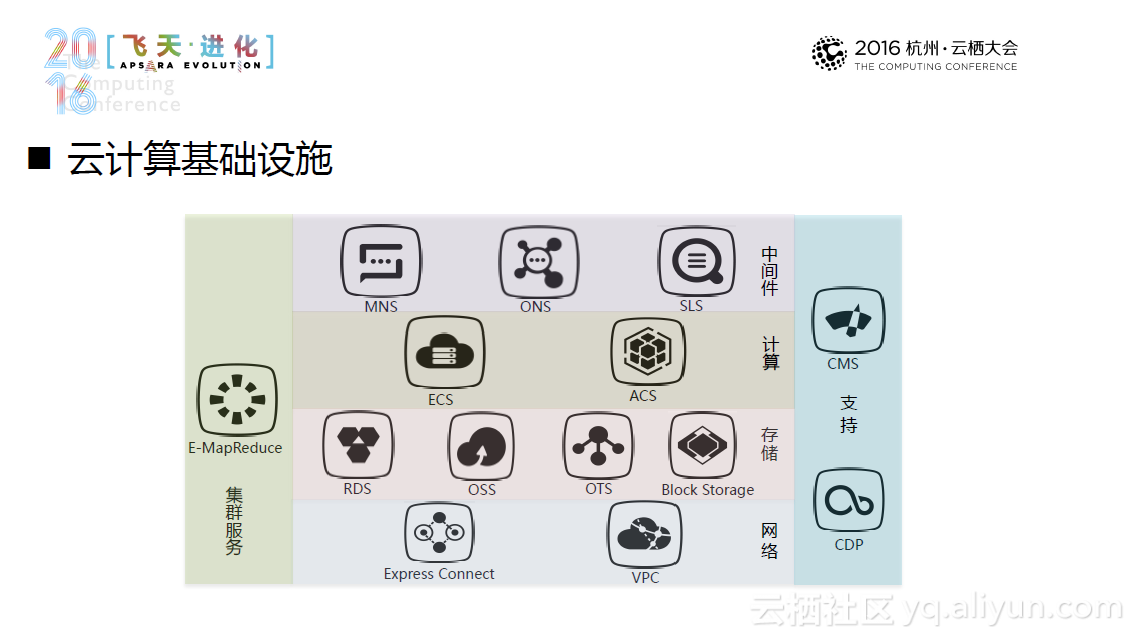
Hadoop部署一般可大致分为传统集群部署和云上集群部署。具体而言,对于传统集群部署,存储和计算是重点,计算能力加上存储能力大致等同于这个集群的能力。传统集群往往包含很多数据“中心”,并以集群混部的方式部署。在理想情况下,一个集群系统往往希望产生更少的数据迁移,并且达到更高的资源利用率。然而在现实中,当带宽逐渐不再是稀缺资源,磁盘不在是承载计算的主战场时,计算和存储这两者之间便会随之产生木桶效应,造成集群的资源浪费。同时,随着人们对于本地数据和远程数据对比逐渐深入,混部的劣势开始逐渐暴露出来。这些劣势包括更大的集群资源浪费、更差的集群扩展性以及不再万能的数据本地化,并且引发了人们对于混合部署的合理性的探讨。
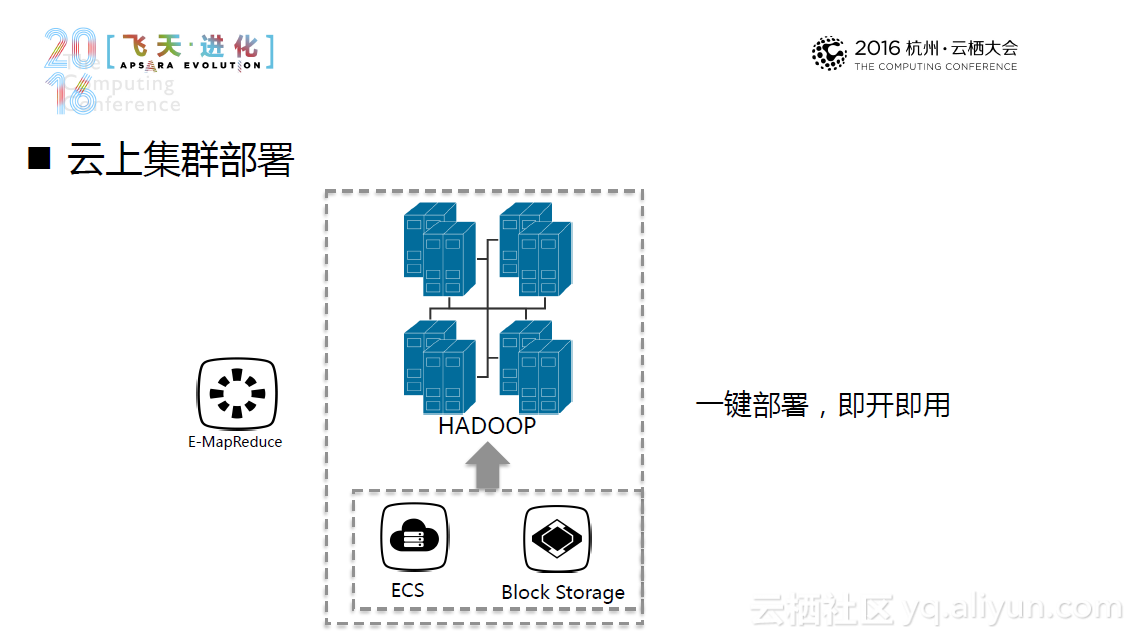
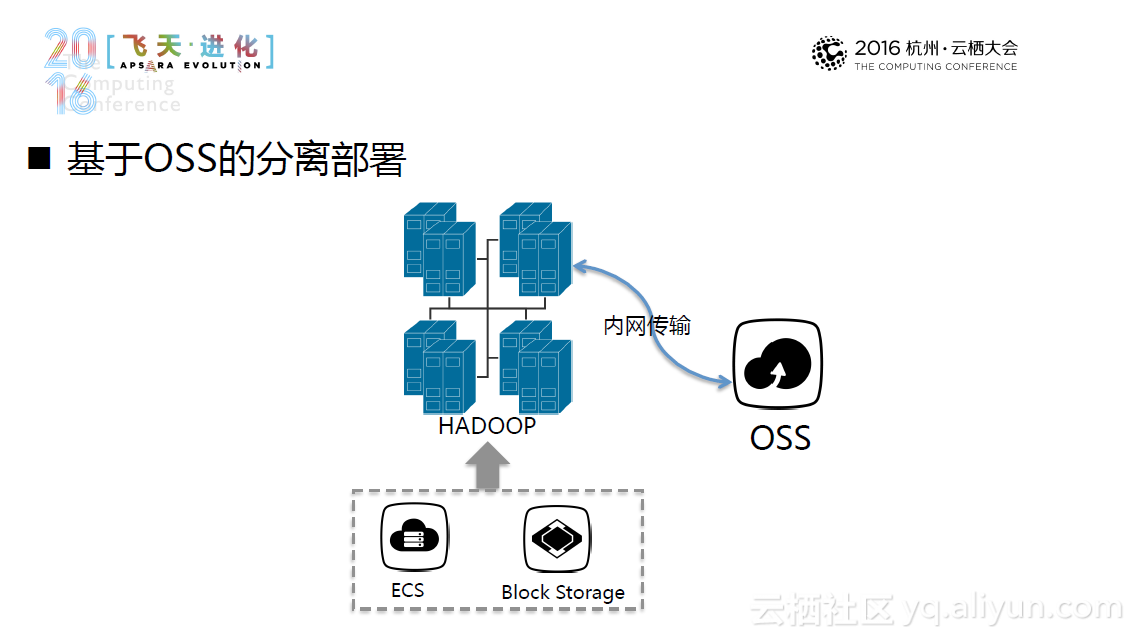
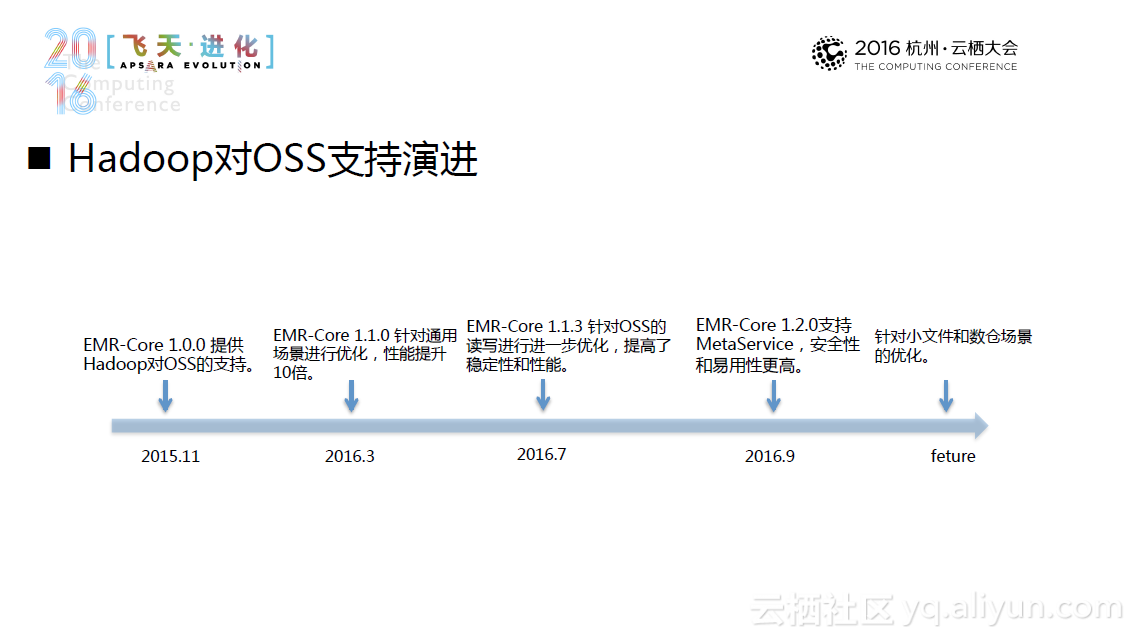
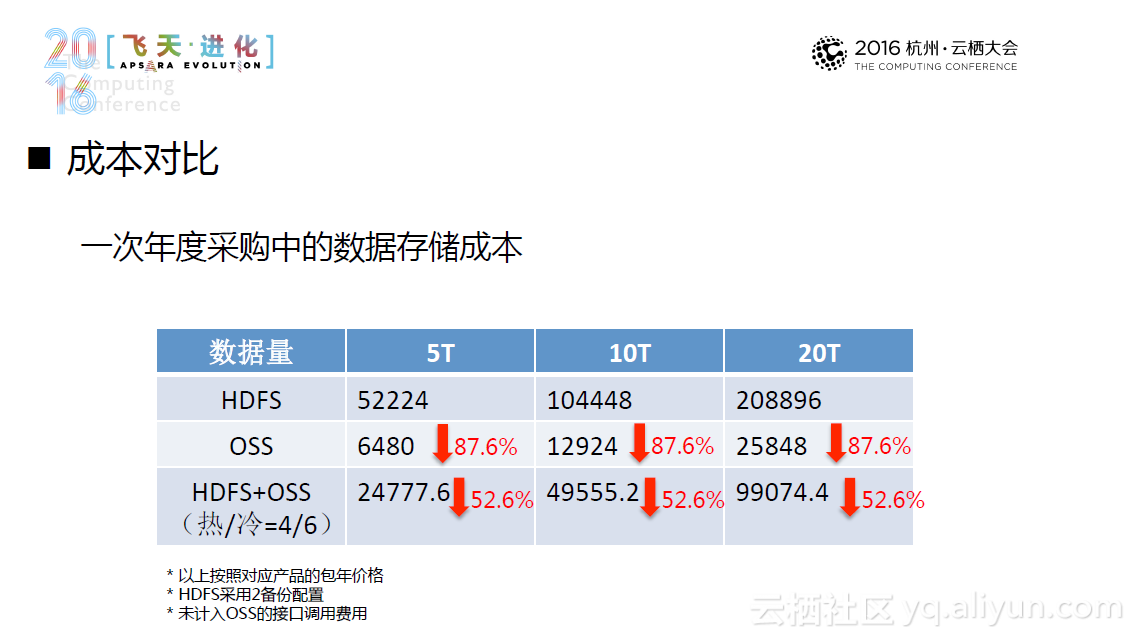
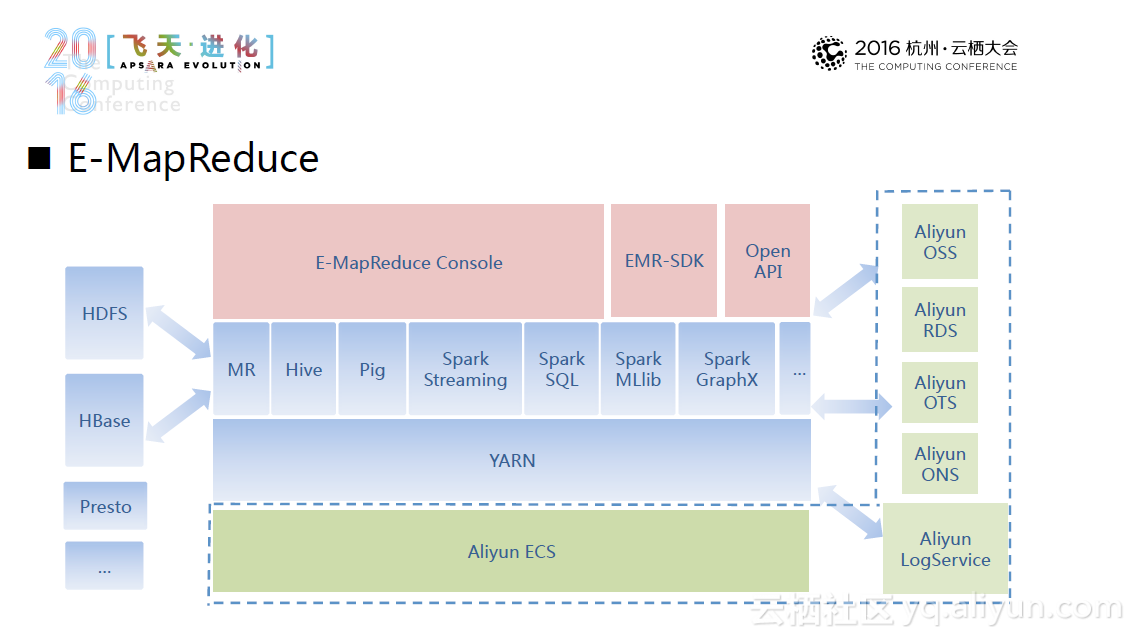
另外一种更新颖的方式是云上集群部署方式。它利用了现有的完备的云计算基础设施在云上集群部署,并且可以达到“一键部署,即开即用”的程度。当然,云上部署也面临储存成本高、储存质量下降等新的挑战。所以,一种新的替代方案--Hadoop+OSS出现了,这种方案基于OSS的分离部署,利用Hadoop对OSS的支持,进行了针对性的优化,未来系统将主要针对小文件预取和缓存和元数据视图系统进行优化。目前,这一方案经过测试,性能达到预期要求,并且还能节省不少的计算成本和存储成本。